Web scraping that survives at scale
We turn any website into clean, structured data you can actually use. Block-free scrapers and full data pipelines, built in Python, delivered on your schedule in the format you need.
If it's on a website, we can collect it
We have built scrapers across very different kinds of sources. Whatever the site, the data ends up clean and in one shape.
E-commerce & marketplaces
Products, prices, variants, stock, images and reviews from stores and marketplaces.
Real estate & rentals
Listings, pricing, photos, agent details and price history from property portals.
Social media
Posts, engagement, media and profile data from public accounts at scale.
Directories & leads
Business listings, contacts and B2B lead data, cleaned and deduplicated.
Reviews & ratings
Customer reviews, ratings and sentiment data for research and monitoring.
Search results & listings
Result pages, rankings and aggregated listings across many sources.
A full pipeline, not just a script
Anyone can grab a page. The value is in everything around it: staying unblocked, cleaning the data, and getting it to you reliably.
Scrape
A distributed scraper pulls the data at volume, using proxies and real browsers to stay block-free.
Clean & validate
We standardise, deduplicate and validate every record so the data you get is actually usable.
Store
Validated data lands in MongoDB or your database, with raw responses kept for re-processing.
Deliver
Clean CSV, JSON or Excel sent where you want it: email, Google Drive, S3 or Slack, on a schedule.
The hard part is keeping it alive
Most scrapers work for an hour and then get blocked or quietly break. Ours are built to run for years.
Block-free at scale
Rotating residential proxies (Bright Data, Zyte), real browser automation and smart throttling keep collection running where naive scrapers get banned.
Built to scale
We have shipped scrapers that handle millions of records across hundreds of cities and sources without falling over.
Clean, trustworthy data
Validation, deduplication and monitoring mean you get accurate data, not a pile of half-broken rows you have to fix yourself.
Delivered, not dumped
Scheduled runs, notifications and the exact format and destination you need. You get fresh data without lifting a finger.
Scraping projects we've shipped
Real pipelines delivering clean data to real clients. See the full case studies on our work page.
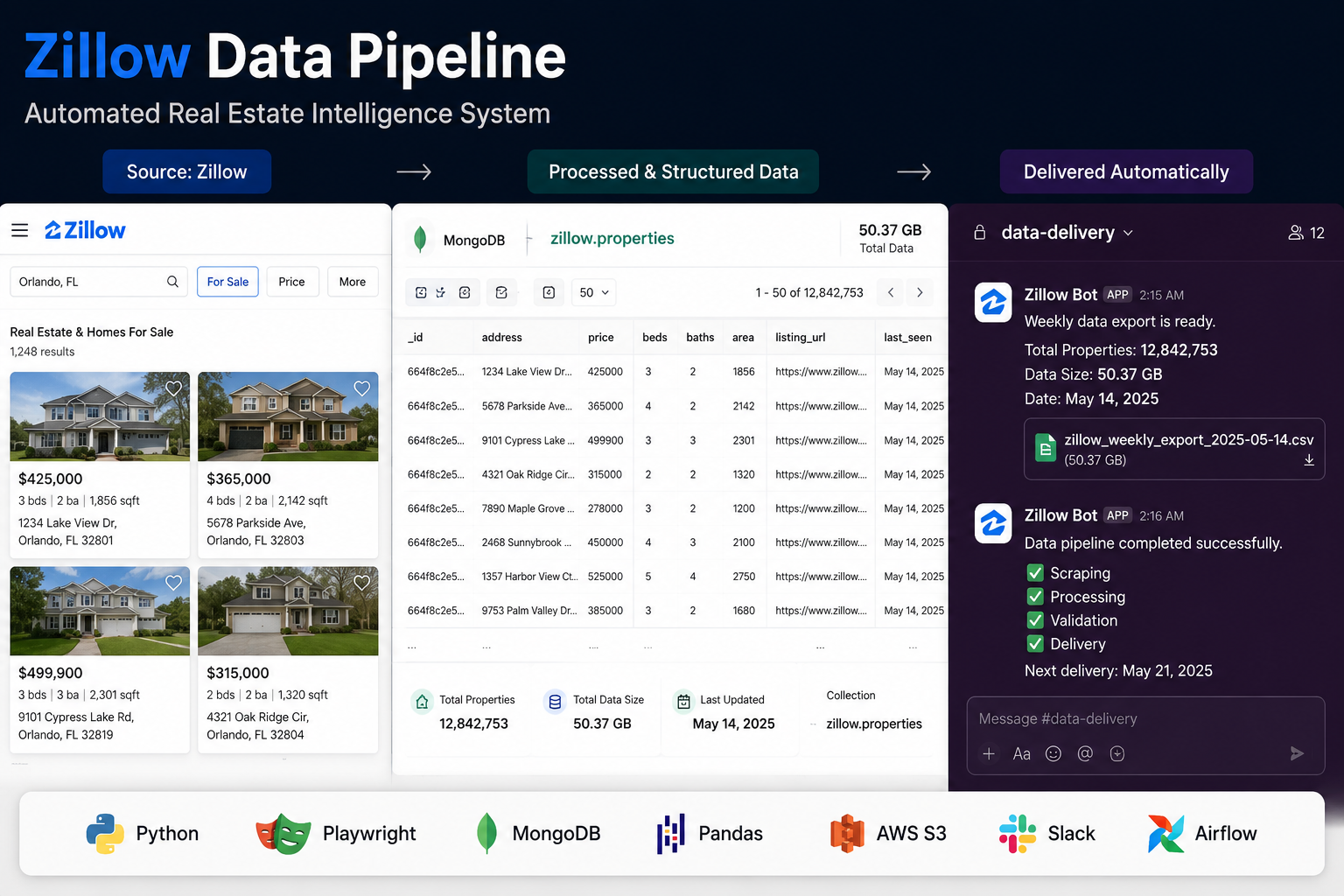
High-Volume Zillow Scraping & Weekly Data Pipeline
A 24/7 scraping and ETL pipeline that extracts full Zillow listing data at massive scale, then cleans, stores, and delivers fresh datasets to the client every week.
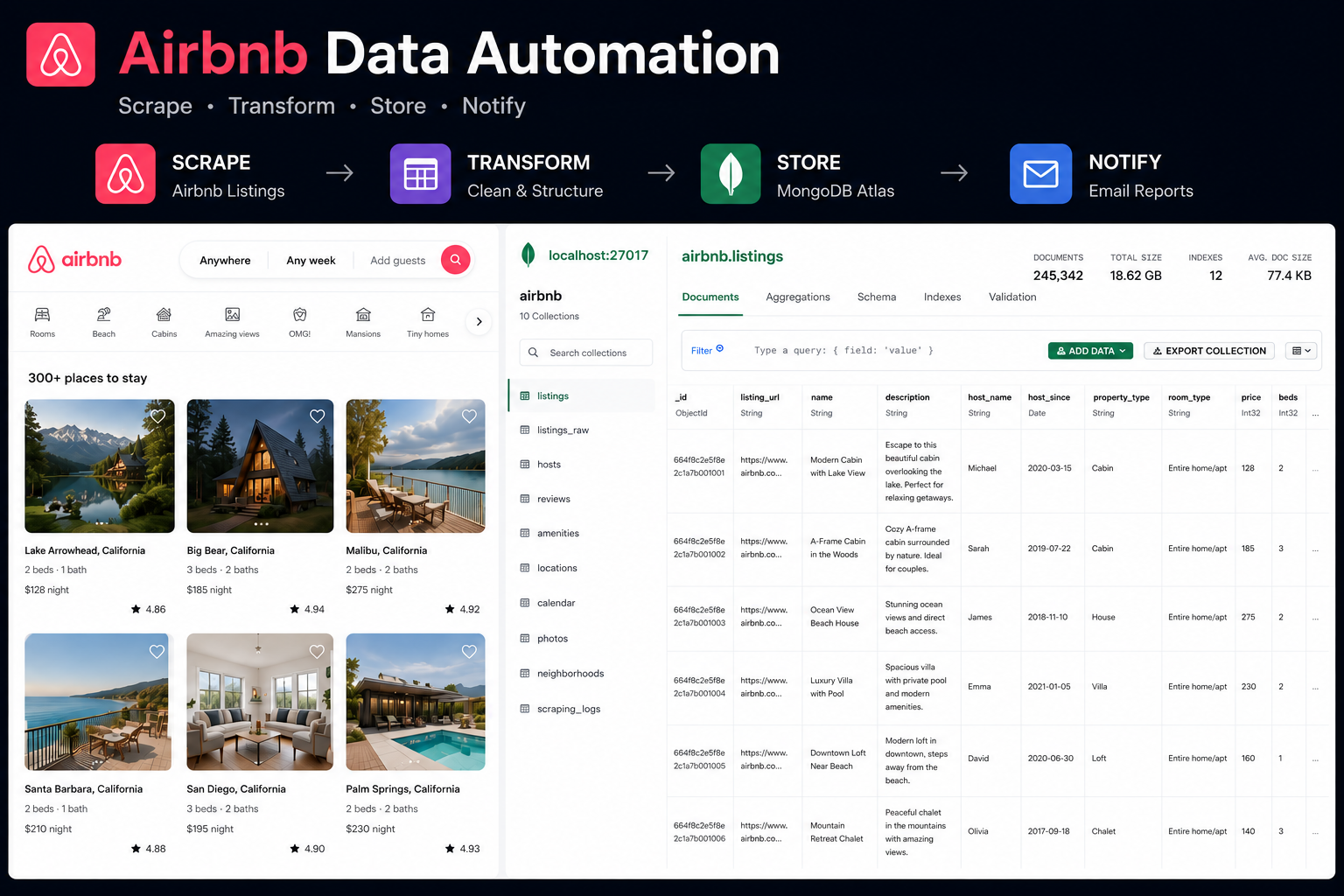
Large-Scale Airbnb Listings Scraper & Data Pipeline
A scalable Airbnb scraper that extracted 100,000+ public listings (details, pricing, images, reviews, owner info), cleaned them, and delivered structured CSV data to the client.
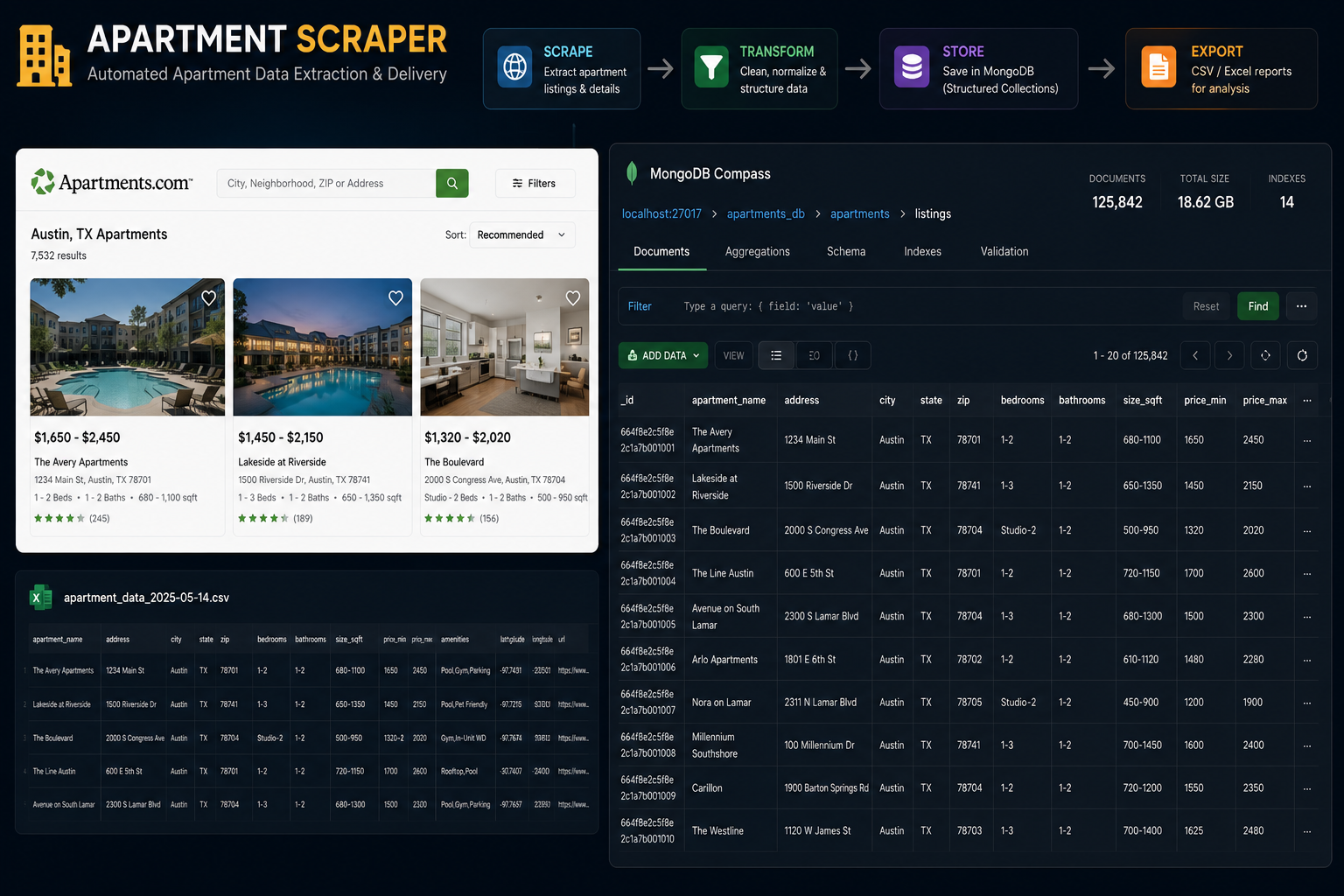
High-Volume Apartment Listings Scraper & Data Pipeline
A scalable scraping and ETL pipeline that collects apartment rental listings across many sources at scale, then cleans, structures, and delivers fresh datasets to the client on a schedule.
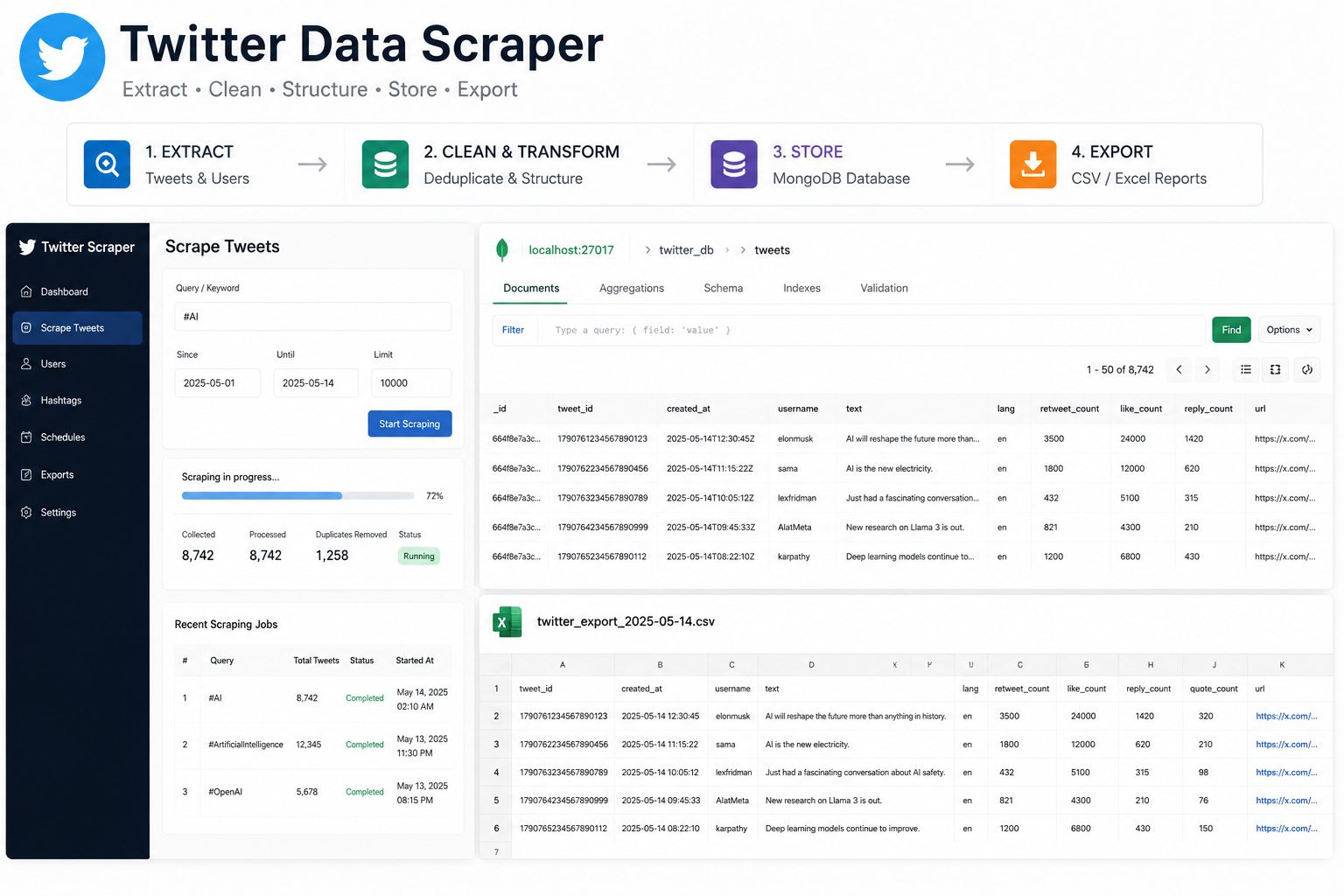
Large-Scale Twitter (X) Social Data Scraper
A scalable Twitter (X) scraper that archived 2,000,000+ posts and engagement data from 500+ profiles, with incremental updates and clean exports for analytics.
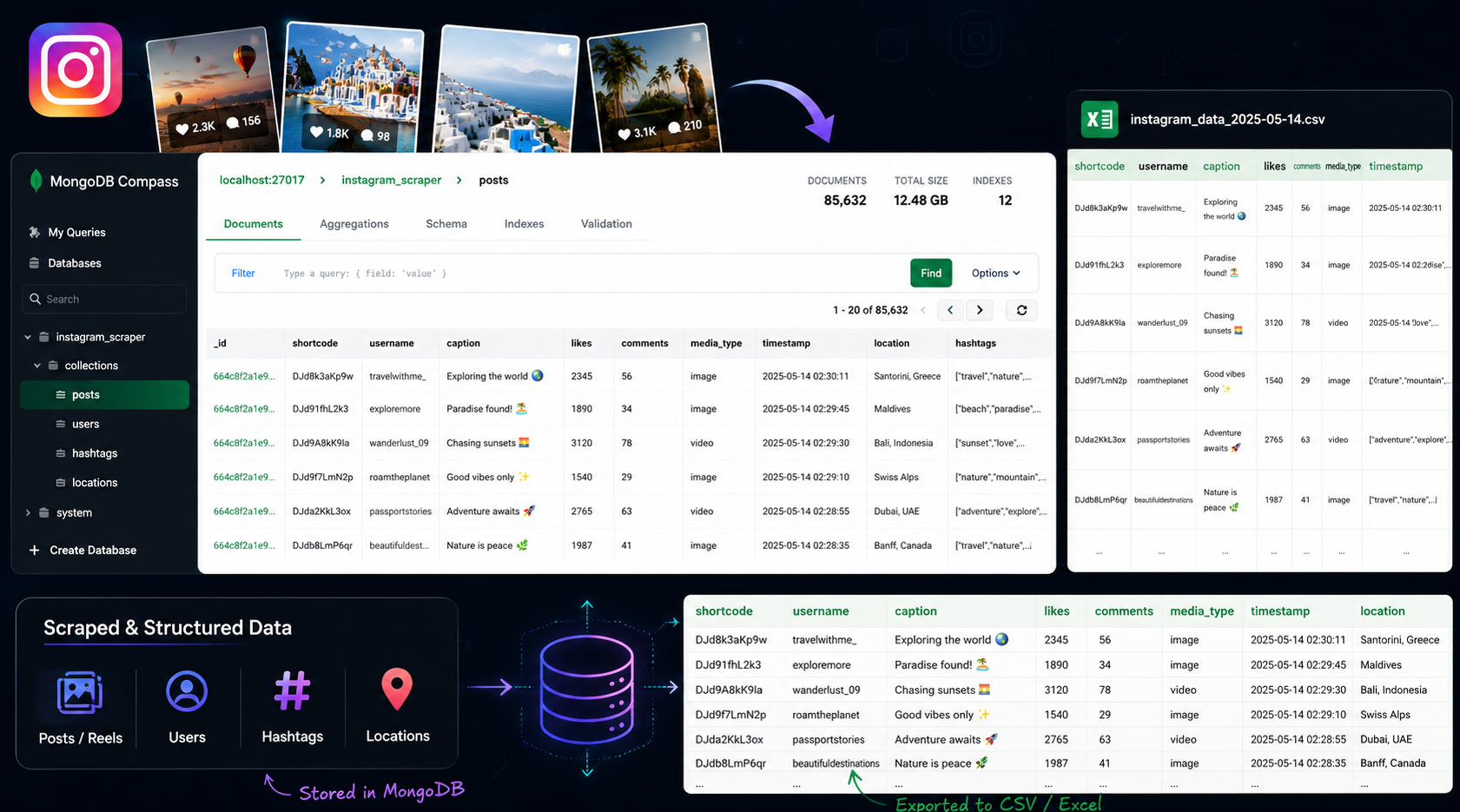
Instagram Data Extraction Tool – Content Scraper
A custom Instagram scraper that collected 200,000+ public posts and 10,000+ profile bios, extracting media, captions, engagement, and bio data, then delivered clean CSV files.
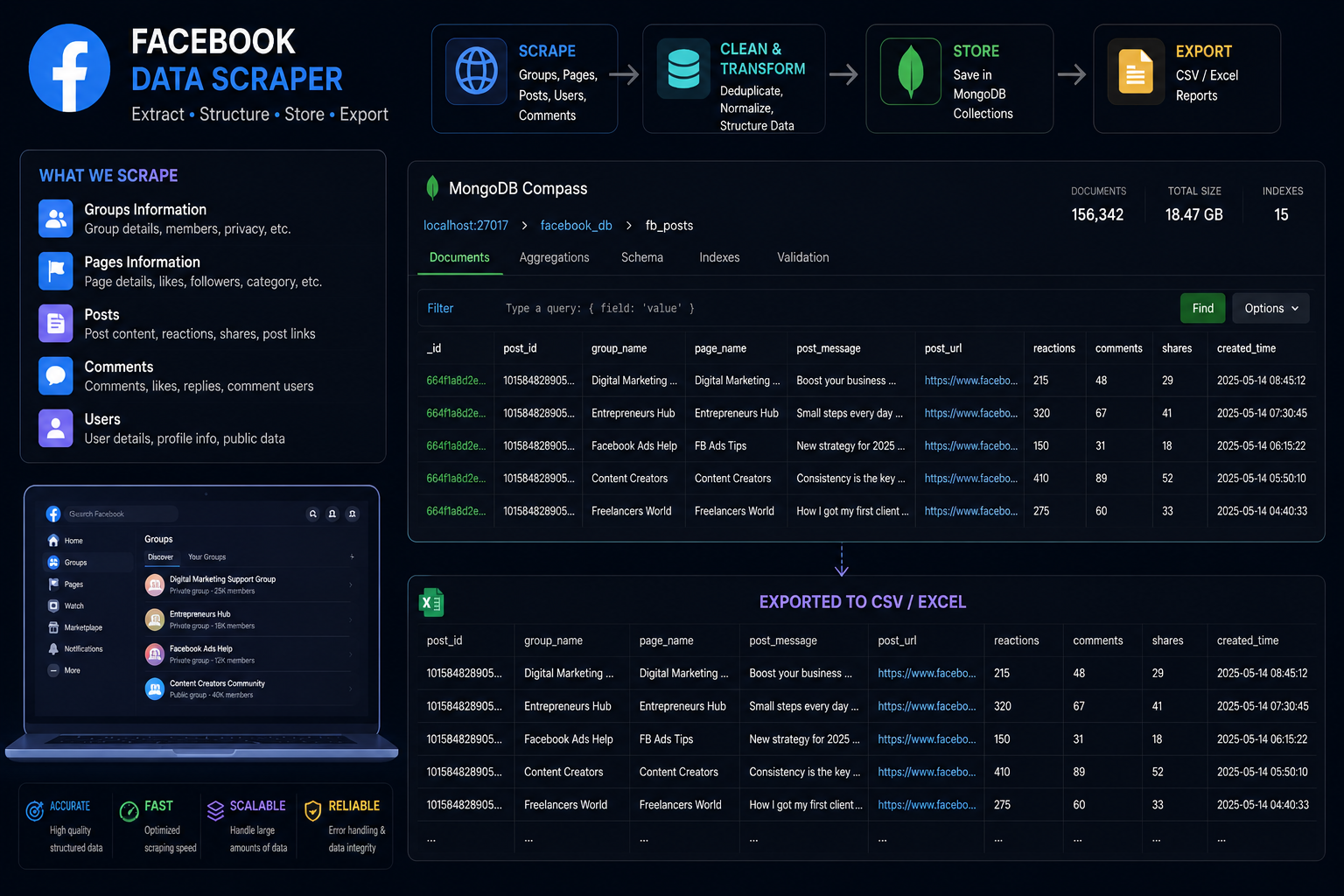
Facebook Post & Marketplace Scraper
A robust scraper and ETL pipeline that extracted 400,000+ records from Facebook groups, pages, and Marketplace, then delivered clean, structured CSV/Excel datasets to the client.
Tools we scrape with
What clients say about our scraping work
The team has deep expertise in web scraping. They successfully completed multiple milestones for me, always delivering accurate and high-quality data. Their ability to handle complex scraping tasks, work with proxies, and overcome site restrictions is truly impressive. Communication was smooth throughout, and they consistently delivered work on time. I highly recommend them to anyone looking for a skilled and reliable scraping partner. Will definitely work with them again!
It was a pleasure working with the team on a web scraping project involving over 15 milestones and multiple websites, and the results have been outstanding. They consistently delivered accurate solutions, met tight deadlines, and went above and beyond to ensure the project's success. Communication was seamless, and they demonstrated deep technical expertise, adaptability, and professionalism throughout. I highly recommend them to anyone in need of a skilled and reliable partner for web development or web scraping!
Strongly recommend the team, very good quality work with a good understanding of the subject. I wish them all the best.
Web scraping, answered
Is web scraping legal?
We focus on publicly available data and work within each site's terms and applicable rules. If a request heads into territory that isn't advisable, we tell you honestly rather than just taking the job.
Won't the website just block us?
Not if it's built properly. We use rotating residential proxies, real browser automation and careful throttling so collection stays reliable at volume. Handling blocks is the core of what we do.
Can you scrape sites that load data with JavaScript?
Yes. We drive real browser engines with Playwright and Selenium, so dynamic content loads exactly as it would for a person, including data that only appears after scripts run.
How do you deliver the data?
Clean CSV, JSON or Excel, sent wherever you want it: email, Google Drive, a database or S3. We can run it once or on a recurring daily or weekly schedule with notifications on each run.
How fresh can the data be?
Anywhere from a one-off snapshot to scheduled refreshes every week or day. For ongoing needs we set up a pipeline that keeps delivering without you having to ask.
What happens when the site changes its layout?
We build in validation and monitoring so we catch layout changes early and fix the scraper before any bad data reaches you, instead of finding out weeks later.
Need data off a website?
Tell us the source, roughly how much data, and how you want it delivered. We'll come back with a clear plan and a real number.
Start a project