Data pipelines that just keep running
We turn messy, scattered sources into clean, structured data, delivered automatically on a schedule. Extract, transform, load, with monitoring and alerts so it runs without you watching it.
Every stage, handled for you
A pipeline is only as good as its weakest link. We own all of them, from the first extract to the alert that lands in your inbox.
Extract from anywhere
APIs, databases, spreadsheets, files and websites. If the data exists, we can pull it into one place.
Transform & clean
Standardise dates, currencies and units, deduplicate, validate, and reshape data to the exact schema you need.
Load anywhere
AWS S3, a database, a data warehouse or your own system. The clean data lands where it's useful.
Schedule & orchestrate
Daily, weekly or hourly runs with Apache Airflow, with dependencies and retries handled properly.
Notify your team
Automated email and Slack alerts on every run, so people know the moment fresh data lands or a job needs attention.
Monitor & validate
Quality checks and monitoring catch bad or missing data before it reaches your reports and decisions.
Extract, transform, load, repeat
The same dependable cycle behind every pipeline we ship, tuned to your data and your schedule.
Extract
Pull raw data from every source on a schedule, keeping the raw copy so it can always be re-processed.
Transform
Clean, validate, deduplicate and reshape everything into one consistent, analysis-ready format.
Load
Write the processed data to S3, a database or warehouse, ready for analytics and downstream use.
Notify & monitor
Fire email and Slack alerts, log every run, and flag anything that drifts from the expected shape.
Anyone can move data once. We make it reliable.
The hard part of a pipeline isn't the first run. It's the hundredth one, still clean, still on time, with nobody watching.
Built to run unattended
Scheduling, retries and logging mean the pipeline keeps delivering week after week without anyone babysitting it.
Data you can trust
Validation and deduplication at every stage, so you act on accurate data instead of debugging silent errors later.
Fresh on your schedule
From one-off loads to hourly refreshes, the data arrives when you need it, in the format and place you want.
Delivered end to end
We own the whole flow, from source to clean file in your inbox or bucket, with notifications so nothing is a mystery.
Pipelines we've shipped
Real pipelines delivering clean data to real clients, on schedule. Full case studies are on our work page.
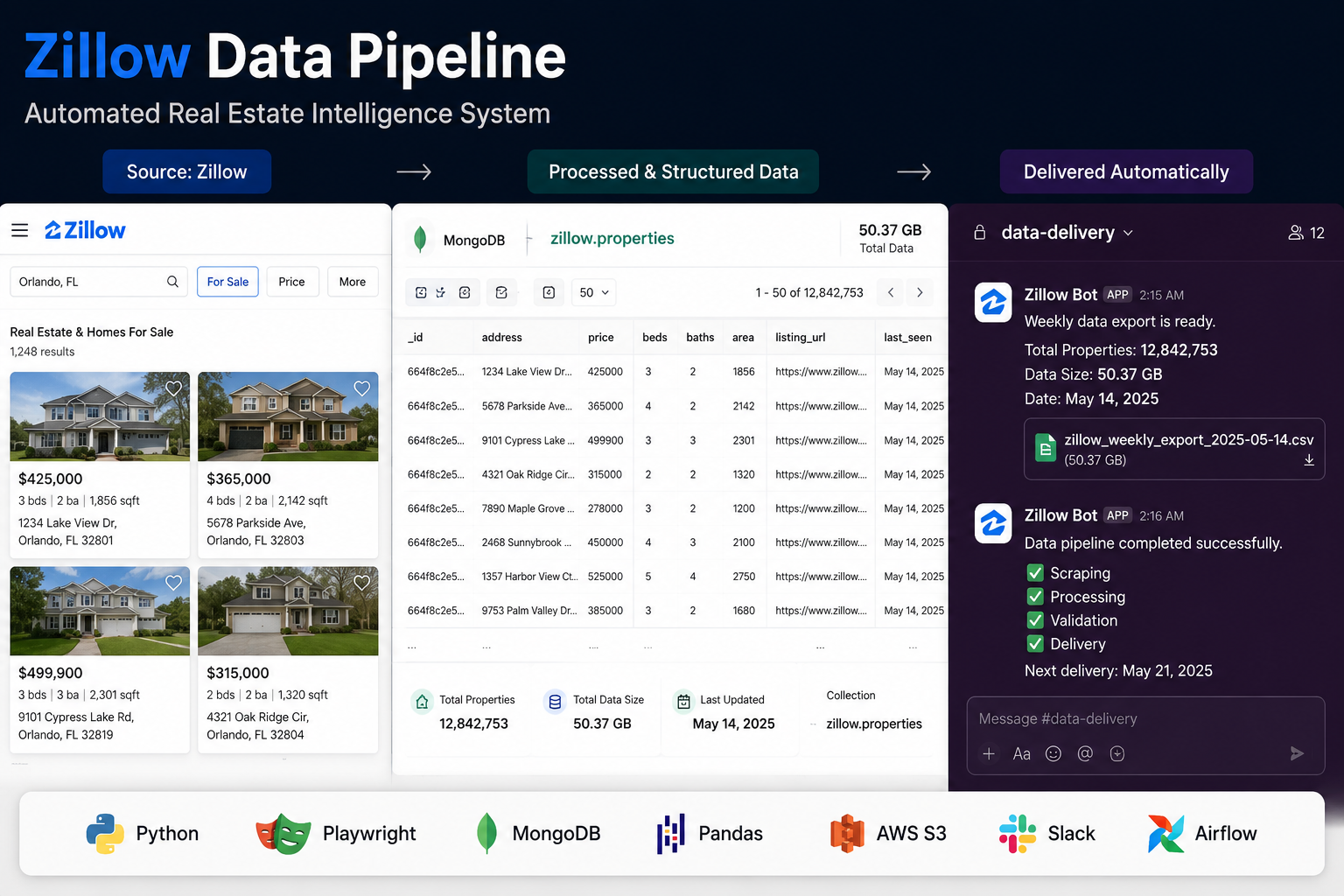
High-Volume Zillow Scraping & Weekly Data Pipeline
A 24/7 scraping and ETL pipeline that extracts full Zillow listing data at massive scale, then cleans, stores, and delivers fresh datasets to the client every week.
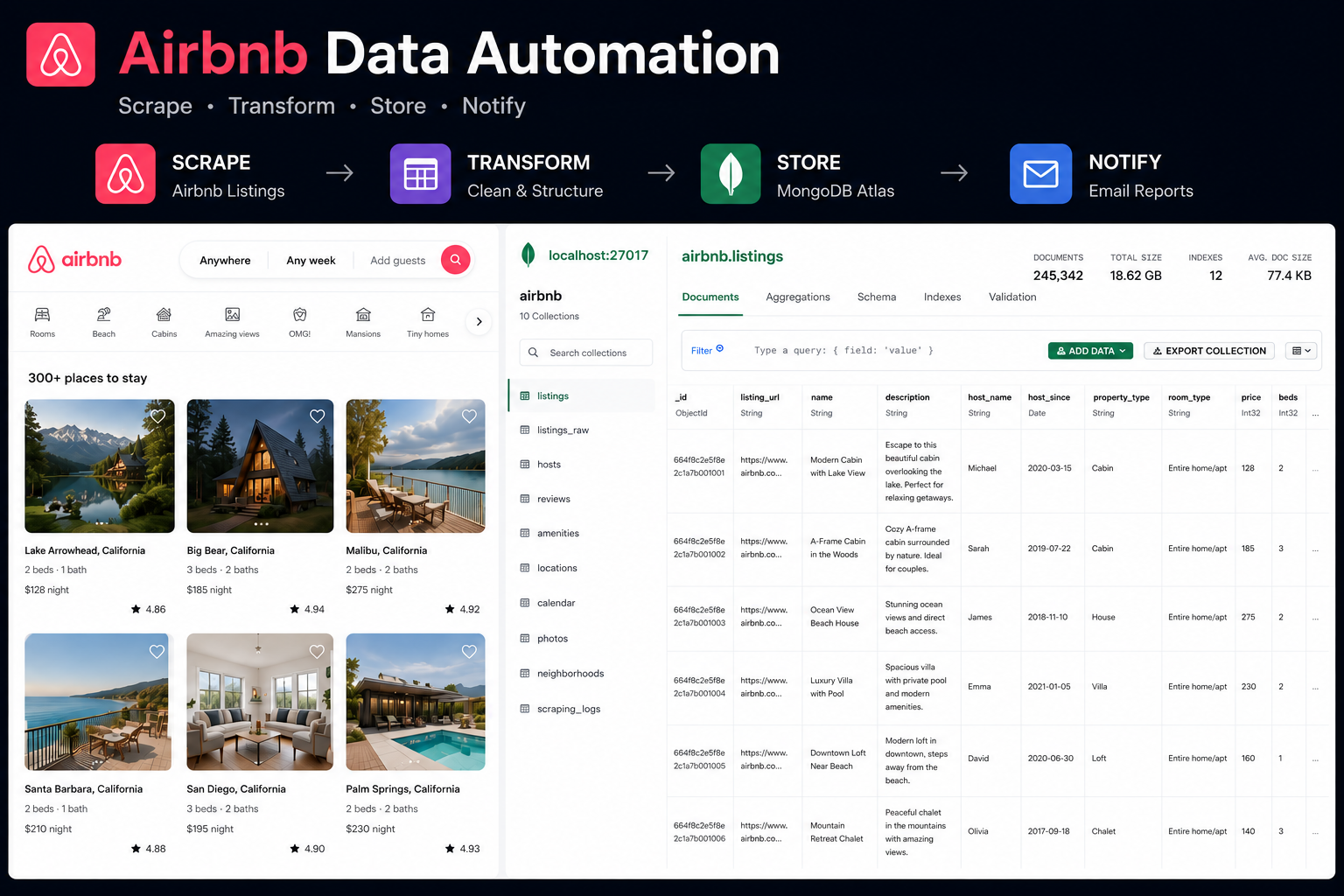
Large-Scale Airbnb Listings Scraper & Data Pipeline
A scalable Airbnb scraper that extracted 100,000+ public listings (details, pricing, images, reviews, owner info), cleaned them, and delivered structured CSV data to the client.
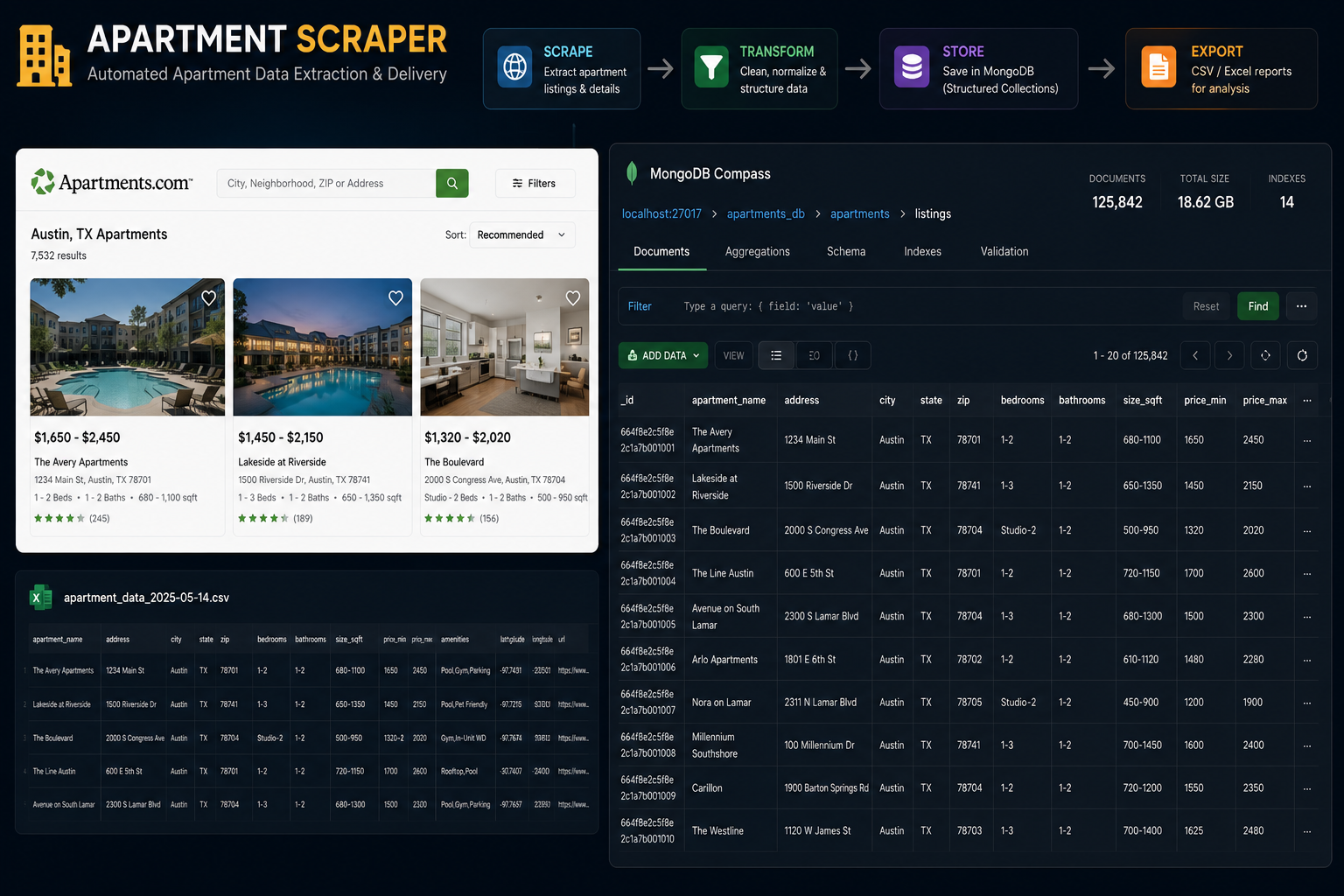
High-Volume Apartment Listings Scraper & Data Pipeline
A scalable scraping and ETL pipeline that collects apartment rental listings across many sources at scale, then cleans, structures, and delivers fresh datasets to the client on a schedule.
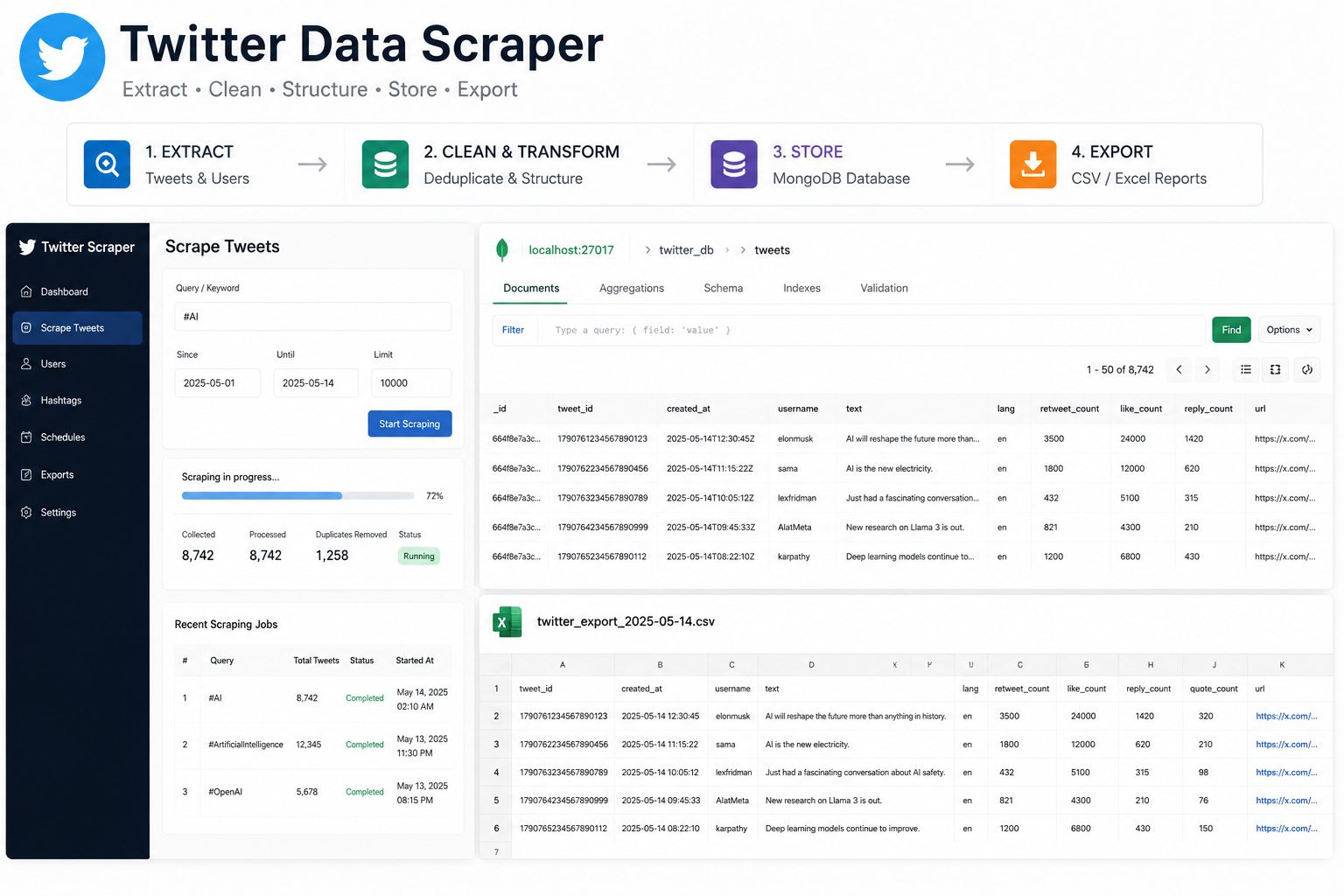
Large-Scale Twitter (X) Social Data Scraper
A scalable Twitter (X) scraper that archived 2,000,000+ posts and engagement data from 500+ profiles, with incremental updates and clean exports for analytics.
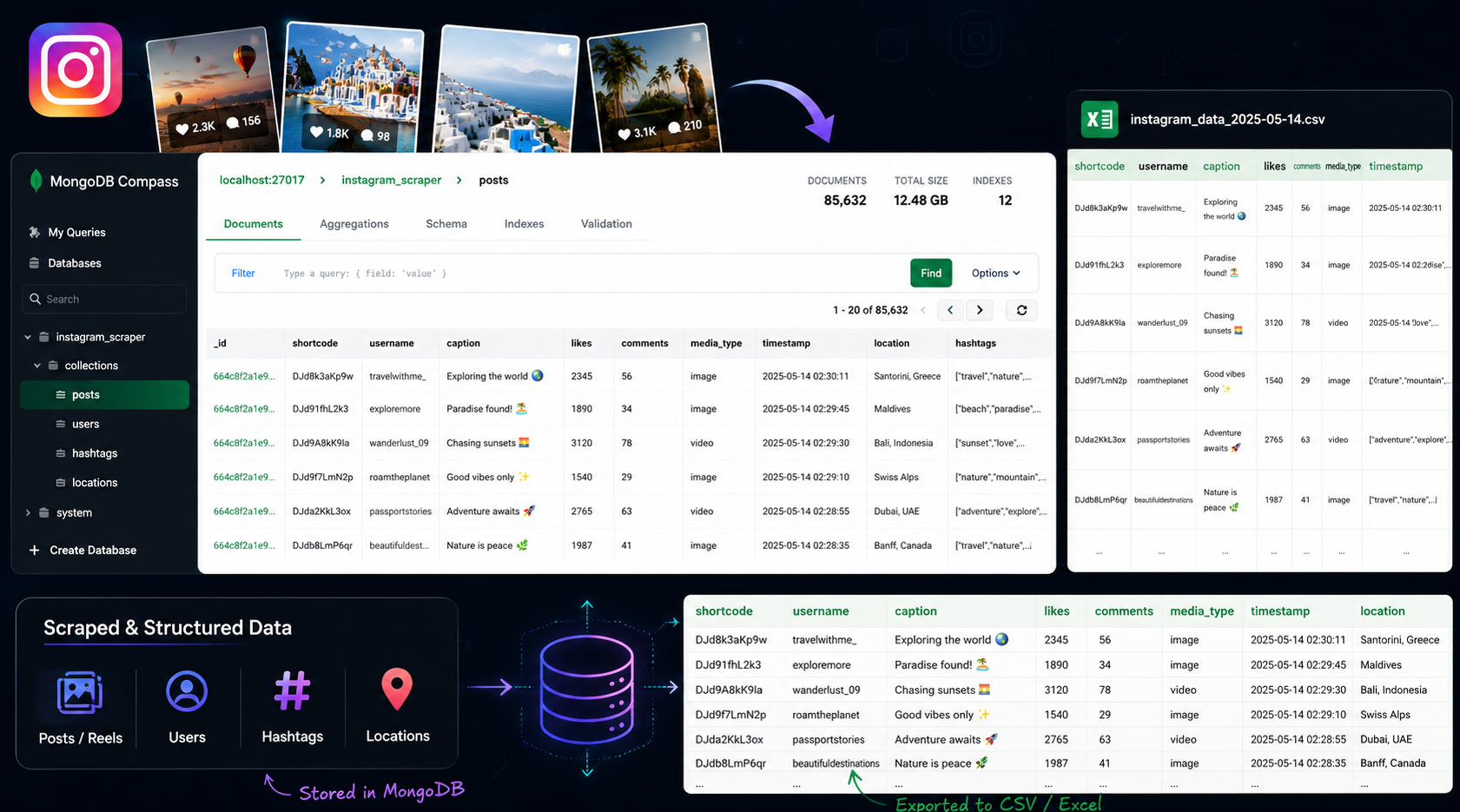
Instagram Data Extraction Tool – Content Scraper
A custom Instagram scraper that collected 200,000+ public posts and 10,000+ profile bios, extracting media, captions, engagement, and bio data, then delivered clean CSV files.
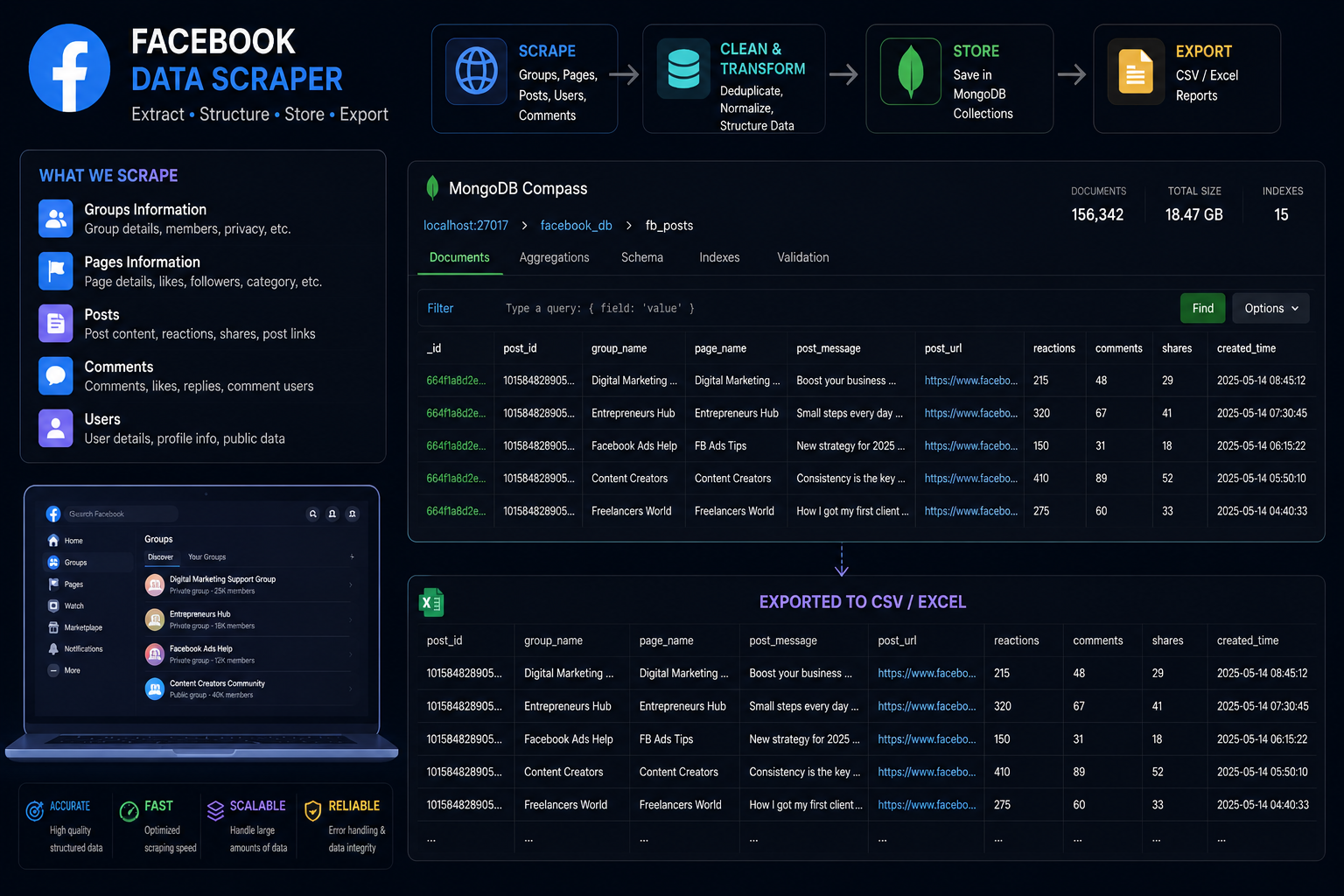
Facebook Post & Marketplace Scraper
A robust scraper and ETL pipeline that extracted 400,000+ records from Facebook groups, pages, and Marketplace, then delivered clean, structured CSV/Excel datasets to the client.
Tools we build pipelines with
What clients say about our data work
The team has deep expertise in web scraping. They successfully completed multiple milestones for me, always delivering accurate and high-quality data. Their ability to handle complex scraping tasks, work with proxies, and overcome site restrictions is truly impressive. Communication was smooth throughout, and they consistently delivered work on time. I highly recommend them to anyone looking for a skilled and reliable scraping partner. Will definitely work with them again!
It was a pleasure working with the team on a web scraping project involving over 15 milestones and multiple websites, and the results have been outstanding. They consistently delivered accurate solutions, met tight deadlines, and went above and beyond to ensure the project's success. Communication was seamless, and they demonstrated deep technical expertise, adaptability, and professionalism throughout. I highly recommend them to anyone in need of a skilled and reliable partner for web development or web scraping!
Strongly recommend the team, very good quality work with a good understanding of the subject. I wish them all the best.
ETL pipelines, answered
What exactly is an ETL pipeline?
Extract, Transform, Load. It's an automated flow that pulls data from your sources, cleans and reshapes it, then loads it somewhere useful, on a repeating schedule rather than as a one-time export.
Where can the data come from, and go to?
Sources can be APIs, databases, spreadsheets, files or websites. Destinations are usually AWS S3, a database, a data warehouse, or delivery straight to your team via email, Google Drive or Slack.
How often can it run?
Whatever you need: hourly, daily, weekly, or triggered on demand. We use Apache Airflow to schedule and orchestrate runs, with retries if something fails.
What happens when a run fails or the data looks wrong?
You get an alert. We build in validation and monitoring so failures and bad data are caught early and flagged on email or Slack, instead of quietly poisoning your reports.
Will it keep working as our sources change?
That's the point of doing it properly. We keep raw data for re-processing and add monitoring so when a source changes, we can adapt the pipeline quickly without losing history.
Can you take over or fix an existing pipeline?
Yes. We're happy to audit, fix or rebuild a pipeline you already have, whether it's slow, fragile, or just nobody understands it anymore.
Tired of moving data by hand?
Tell us your sources, what the data should look like, and where it needs to go. We'll design a pipeline that delivers it for you, on repeat.
Start a project